Anthropic
Recent items mentioning Anthropic across the Databricks ecosystem — releases, news, videos, and community Q&A. Updated hourly.
Anthropic was recognized as a Databricks global partner in 2026, emphasizing AI transformation and agentic AI at enterprise scale 6. Their Claude Fable 5 model is now available on Databricks, governed through Unity AI Gateway 7, and has been instrumental in solutions like Ecolab's retail intelligence platform, which leverages Databricks and Anthropic Claude to convert large manuals into real-time answers 10. Databricks' new Omnigent meta-harness for AI agents also provides a unified interface for composition and control across multiple models, including those from Anthropic 239.
Generated daily from the 10 most recent items mentioning Anthropic. Click any [N] to jump to the source.
The `ssh connect` command now supports a `--base-environment` flag for custom serverless session environments. Bundles received fixes for persistent drift in model serving endpoints and spurious updates with `apply_policy_default_values` on job tasks.
Launch HN: Parsewise (YC P25) – Reason Across Documents with an API
Hi all, it’s Greg and Max, founders of Parsewise here (https://www.parsewise.ai/api). Parsewise transforms a bucket of unstructured data into schema compliant data, retaining lineage for values resolved across documents. Imagine giving Claude a bunch of files and asking for a CSV or JSON output. If you have tried this, you know both the system limitations (number of files, type of inputs, cost, latency) but also the human-facing challenge of having no way to validate the results quickly. We solve both. We help tech teams simplify their unstructured data ETL, and loop in business experts for the definitions and for instant validation. Here is a video with a few use cases: https://www.youtube.com/watch?v=dbRllnnh47w Parsewise in the words of someone coming to us: ”I need to extract information from insurance policy PDFs, phone calls that have been transcribed, emails, etc. I am NOT looking for something that would just extract data point by data point, page by page into a structured well-defined schema but more something more agentic that can understand that information might be across documents and that it should reason over what to extract.” We started the company based on a decade of experience (and pain) in complex data transformation and data analysis / synthesis. Greg was building both classical ETL and implemented AI workflows at Palantir. At Bain, Max did highly complex data analysis in the financial sector, similar to many of our customers. Parsewise works by taking in a bucket of data (think hundreds or thousands of pdfs, excels etc.), and outputting schema compliant data where every single value is traceable down to word level citations across multiple documents in the bucket. We provide API customers with ways to show the lineage in their own applications, or they can use our platform for internal operations. At the core of the data processing we have self-improving agent definitions. They define the acceptable sources, the logic for resolving or combining values, and the rule for highlighting uncertainty to the end user. The underlying tech is model and cloud agnostic and can be deployed in private networks. We have seen the best results with Gemini models for visual reasoning, achieving SOTA (beating Claude Fable) on the strongest grounded reasoning benchmark we have found (Databricks OfficeQA). Notably, we focused more on the “human harness” rather than the model harness, leaning into the actual friction we saw in uptake, which is around verifiability. That means optimizing the time and clicks required to trust the outcomes. We use vLLMs for parsing, and then we use small models for efficient large scale exhaustive search. Unlike RAG, we do not sample; instead, we exhaustively find all relevant values for a given query. We use larger models for decision making around resolutions and flagging inconsistencies to users. This exhaustiveness and explicit value sourcing is unique to our platform, and it goes beyond the first step of data parsing that many existing providers cover. We would love to welcome builders and tinkerers to try Parsewise on your complex document challenges. We have a ton of ideas on how we can expand the product and make it better, but would appreciate feedback and ideas from the community! --- top comments --- [whinvik] Document parsing is top of my mind lately because in some of the areas we work on the bottleneck is starting to become being able to query documents the same way one queries an api. I keep thinking the most obvious analogue is we need some way to represent documents the same way we can represent structured data in parquet. Parquet allows easy range bases queries and there is so much tooling built around Arrow. But for documents I keep hitting a wall to figure out what the right abstractions are. Parquet allows filterable metadata. But what such metadata is there for documents. Then there is the arbitrrariness of chunking, vectorization. If we could just do this in a […truncated]
 Releases
ReleasesIntroducing Omnigent: The Ultimate Meta-Harness for AI Agents
Omnigent is a new open-source meta-harness for AI agents that provides a unified interface for composition, control, and collaboration across multiple models and agent workflows. It enables stateful, data-centric policies for guardrails and allows real-time sharing and steering of live agent sessions with teammates.
 News
NewsAI Stack Explained in 3 Layers (LLM, Agent Harness, Omnigent)
The AI stack now includes a third layer, the meta harness, which sits above individual agent harnesses. This meta harness, exemplified by Databricks' open-sourced Omnigent, allows for routing queries to appropriate agents and orchestrating tasks across multiple agents, enabling seamless interaction and context sharing between them.
 Tutorials
Tutorials✅ How Transformers Work - Attention Explained Step by Step | Chapter 06
The video explains the Transformer architecture, detailing how it processes text input through tokenization, embedding, and a stack of Transformer blocks to generate the next token. It breaks down the attention mechanism, multi-head attention, and feed-forward layers within a Transformer block, highlighting the differences between encoders and decoders.
MLflow 3.14.0 introduces new GenAI features including agent onboarding, durable tracing for Claude Code, review queues for traces, and a revamped evaluation dataset UI. It also includes a new LLM Playground for prompt iteration and changes the default serialization format for several MLflow model flavors to `skops` or `pt2`.
Databricks announces 2026 global partner awards
Databricks announced its 2026 global partner awards, recognizing over 60 Consulting and System Integrator and ISV partners including Accenture, Deloitte, Anthropic, and NVIDIA. This year's awards emphasize AI transformation, lakehouse modernization, Unity Catalog governance, and agentic AI at enterprise scale.
Announcement | Claude Fable 5 on Databricks, Governed through Unity AI Gateway
Omnigent: A Meta-Harness to Combine, Control and Share Your Agents
--- top comments --- [saj1th] Been exploring loop engineering. Addy Osmani has a good post on it: https://addyosmani.com/blog/loop-engineering/ The hard part of loop engineering IMO is the machinery around it, and omnigent sits above pi, claude, codex, etc. and wraps each in a uniform api. The things it adds are exactly that machinery. - Parallel git worktrees so concurrent agents don't step on each other. - Approval and cost policies enforced at the harness layer rather than living in a prompt the agent can talk its way around. - A maker/checker split where the reviewer can run on a different vendor than the writer, which is a more honest check than a second pass from the same model with the same blind spots. [dpbrinkm] I can see this being useful if only for the fact I can search all my conversations with my 50 different agents on different providers easier. I spend so much time looking through my cc/codex session or the desktop app or Hermes agent or antigravity session (back when I used that). Hopefully having a layer above will abstract that away. If I understand it correctly the meta harness will help me scan across all sessions and not have to drop into individual ones. [iamfreee] very similar to https://github.com/kdlbs/kandev/, which also supports multiple different agent harnesses working on the same task
Introducing Omnigent: A Meta-Harness to Combine, Control and Share Your Agents
Omnigent, an open source meta-harness, is now available to combine, control, and share your AI agents across various models and interfaces. It enables building agent teams, controlling them with policies, and sharing live sessions with teammates.
How Ecolab rebuilt retail intelligence on Databricks and Anthropic Claude
Ecolab rebuilt retail intelligence on Databricks and Anthropic Claude, converting 700-page FDA manuals into real-time answers for frontline staff using Foundation Model APIs and cutting compliance report compilation from two weeks to under two minutes. The solution, a native Databricks App with Lakebase Postgres and Unity Catalog, unifies nine siloed data sources and employs a multi-agent orchestration framework with Judge LLMs and MLflow tracing for personalized, continuously refined intelligence.
Claude Fable 5 is now available on Databricks, fully governed through Unity AI Gateway
Claude Fable 5 is now available on Databricks, accessible through Unity AI Gateway for centralized governance, cost controls, and observability. This Anthropic model offers state-of-the-art performance across enterprise workflow automation, agentic search, data reasoning, and multimodal document understanding.
 News
NewsAnthropic's SpaceX Deal, ClawPilot, and Databricks Agent-centric Cert | AI Newsround - May 2026
Anthropic signed a deal with SpaceX for AI supercomputing infrastructure, signaling the importance of compute supply in AI development. Google and Microsoft launched personal AI agents, Gemini Spark and Microsoft Scout, emphasizing ecosystem integration, trust, and governance.
The SDK now better detects AI agents by honoring the Vercel AI_AGENT environment variable and passing through unrecognized agent names in the User-Agent header. This improves visibility for various AI agent versions and custom names.
Claude Mythos & Databricks LakeWatch
Beyond parsing X12: Closing the gap for revenue cycle workflows in healthcare
Healthcare billers now have an operational workbench built on Unity Catalog gold views, providing a purpose-built UI with a denials queue, remittance drawer, and timely-filing age alerts directly on their fully parsed 835/834/837 EDI data. This solution integrates GenAI via Databricks Foundation Model APIs to auto-draft appeal letters, moving billers beyond manual spreadsheet and SQL work to review and approve instead of writing from scratch.
MLflow 3.13.0 introduces a new Role-Based Access Control system with an Admin UI for managing users and permissions, alongside trace retention and auto-archival to object storage. This release also includes one-click observability for coding agents, new engines for MLflow Assistant, and an official Helm chart for Kubernetes deployments.
Migration from Synapse to Databricks SDP
HELLO HELLO! 👋 I'm currently running a POC to migrate our company from Azure Synapse over to Databricks SDP, and I'm looking to lean on the hive mind here. Has anyone done this recently? To speed things up, I’ve been using GenAI (Claude + Genie Code with Databricks skills). On the surface, it’s great and the code it spits out actually runs fine. The problem is the sheer volume of code is absolutely insane. Trying to reconcile and verify it line-by-line is becoming a nightmare as I just don't fully trust the output blindly. To make matters worse, I can't even do a proper "apples-to-apples" comparison of the actual data outputs: * **Synapse:** Has our full historical data. * **Databricks:** Only has the last 3 months of data loaded for this workspace POC. How do you validate massive amounts of AI-translated code when you can't even compare full data volumes? Thanks in advance!
The SDK now supports more granular AI agent detection in User-Agent headers and passes unrecognized values as-is. Several API changes introduce new fields for dashboards, apps, ML materialized features, and synced table statuses, along with a `Revert` method for Lakeview dashboards.
Route Claude Code Through MLflow AI Gateway
MLflow AI Gateway now supports routing Claude Code, providing full observability, budget controls, and guardrails for all your coding agent sessions. This integration requires no changes to your existing Claude Code usage.
MLflow now features a major overhaul of Role-Based Access Control with a new Admin UI and unified permission APIs. It also introduces end-to-end trace archival, Helm charts for Kubernetes deployment, and a new API for stress-testing GenAI agents.
OAuth tokens for interactive logins are now stored in OS-native secure stores by default, requiring re-authentication after upgrading. A new `databricks aitools` command group is introduced for installing Databricks skills into coding agents.
 News
NewsEnhancing your Skills with Databricks Genie Code
Databricks Genie Code is an agentic coding system that allows users to build custom "skills" using markdown files, enabling it to generate code and perform tasks according to specific in-house standards and conventions. These skills provide context-on-demand, ensuring repeatable and consistent output for various engineering tasks like schema documentation or metric view creation.
 News
NewsDatabricks Genie, Unity AI Gateway, Project Glasswing, and Model Mania | AI Newsround - April 2026
Databricks Genie is now the business user home screen for Databricks, offering a unified chat interface, external knowledge store connections, and a mobile app. The Unity AI Gateway, integrated with Unity Catalog, provides comprehensive governance for agentic AI, including permissions, auditing, and policy controls for models and tools.
MLflow 3.12.0 introduces multimodal tracing, allowing storage and rich rendering of PDFs, audio, and images as artifact attachments in tracing spans. It also adds AI Gateway guardrails to prevent unsafe model inputs/outputs and extends coding agent tracing support to Codex, Gemini, and Qwen.
MLflow 3.12.0rc0 introduces enhanced AI agent development features, including automatic tracing for more AI coding assistants and OpenClaw, along with new AI Gateway guardrails for safety checks. It also adds multimodal trace attachments for viewing images, audio, and files in the UI, and a new `mlflow.diffusers` flavor for saving and serving diffusion models.
The SDK now automatically detects AI coding agents and appends agent information to HTTP request headers, while also removing the unused `experimentalIsUnifiedHost` field from `DatabricksConfig`. A bug fix addresses `X-Databricks-Org-Id` header issues for `SharesExtImpl.list()` on SPOG hosts, and several API method paths have changed, which are breaking changes.
WorkspaceExt upload/download and SharesExt list now include the X-Databricks-Org-Id header for SPOG host compatibility. WorkspaceClient.get_workspace_id avoids an API call when the workspace ID is already known, fixing a SPOG host failure.
 News
NewsGenAI - For Data Engineers Agenda & Introduction | LLM & Agentic AI | LangChain & LangGraph | Claude
This video introduces a new course, "GenAI for Data Engineers," designed to teach data engineers how to leverage generative AI, LLMs, and agentic AI. The course covers basics of LLMs, building agents with LangChain and LangGraph, using Cloud Code, and applying agentic AI within Databricks and data engineering workflows.
This release introduces new workspace-level services for supervisor agents and Unity Catalog secrets, along with an update method for tokens. Several existing API methods for data classification, environments, knowledge assistants, Postgres, and warehouses have breaking changes due to path modifications.
This release adds Azure MSI authentication support and improves `.databrickscfg` default profile resolution. It also fixes issues with non-JSON error responses and Databricks CLI token scope mismatches, alongside several API additions and two breaking changes.
MLflow 3.11.1 introduces AI-powered issue detection for agent traces, budget alerts and limits for AI Gateway spending, and a new interactive graph view for visualizing trace hierarchies. It also enhances security with pickle-free model serialization and improves dependency management with native UV support.
Testing and Refining Claude Code Skills with MLflow
MLflow tracing and LLM judges can now test Claude Code skills. This enables a self-improvement loop where Claude Code refines its own abilities.
 Tutorials
TutorialsDatabricks AI Dev Kit Demo - Install, DataGen, SDP, Dashboard
The video demonstrates installing the Databricks AI Dev Kit on a Mac, then uses it to generate synthetic data, create serverless Spark declarative pipelines for a medallion architecture, and build a Databricks dashboard based on the generated data. It highlights how the AI Dev Kit leverages skills and an MCP server to automate these development tasks.
The SDK now automatically detects AI coding agents and appends `agent/<name>` to HTTP request headers. Two new `DisableGovTagCreation` fields were added to `RestrictWorkspaceAdminsMessage` in both `settings` and `settingsv2`.
The SDK now automatically detects AI coding agents and appends agent information to HTTP request headers. Two new `disable_gov_tag_creation` fields were added to restrict workspace admin settings.
This release introduces AI-powered issue identification for agent traces, budget alerts and limits for AI Gateway spending, and an interactive graph view for trace hierarchies. It also includes native OpenTelemetry GenAI convention support, Opencode tracing integration, UV package manager support, and pickle-free model serialization options for enhanced security.
 News
NewsOpenClaw, Databricks Agentic Data Monitoring & more! | AI Newsround - February 2026 | Advancing AI
The video discusses OpenClaw, an open-source framework for AI agents, and Databricks' new agentic data quality monitoring solution. It also introduces Advancing Analytics' Lake Forge and Pantheon, a framework and AI layer for developing scalable Lake Flow pipelines, and highlights new model releases from Anthropic, Google, and OpenAI.
MLflow 3.10.0 introduces multi-workspace support for organizing experiments and models, alongside new GenAI features like multi-turn evaluation, LLM cost tracking, and AI Gateway usage analytics. The UI has been redesigned for improved navigation, and in-UI trace evaluation is now available.
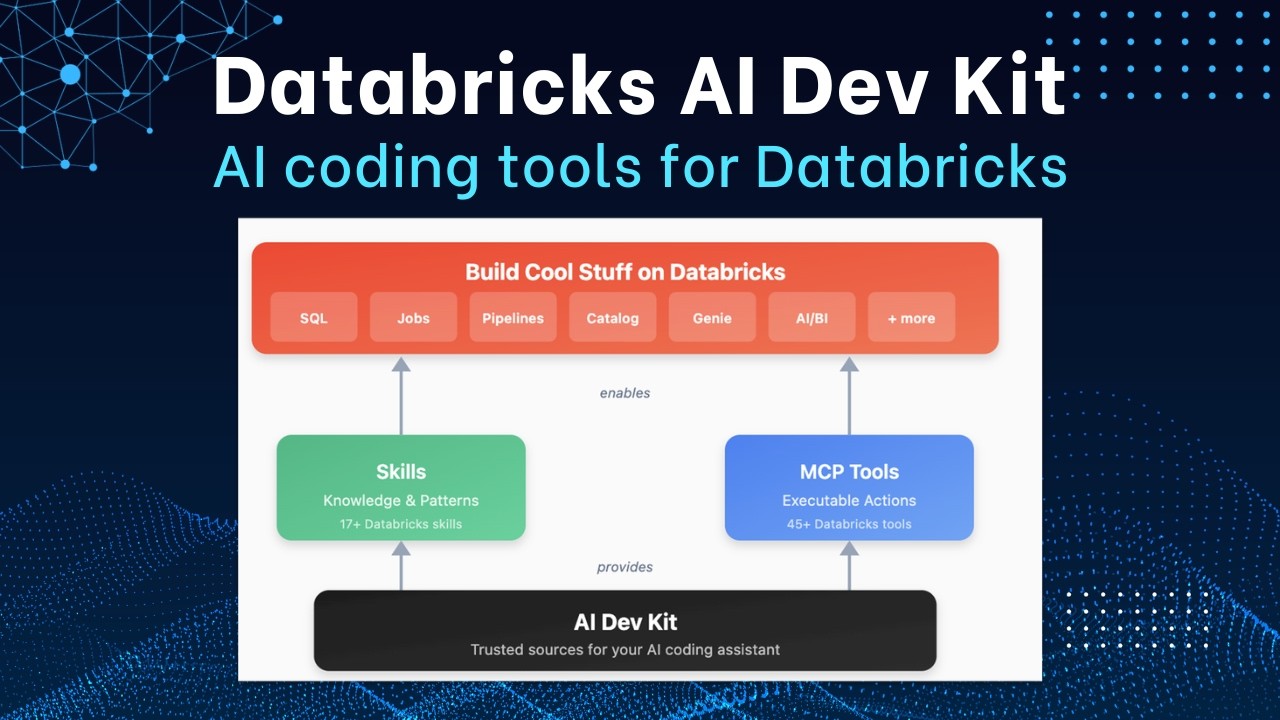 Releases
ReleasesIntroducing Databricks AI Dev Kit - Skills, MCP server, Builder App
The Databricks AI Dev Kit provides agent skills, an MCP server, and a Builder App to enhance AI-driven development on Databricks. It allows users to integrate AI coding tools with Databricks best practices, extending LLM capabilities through specialized functions and offering a chat-based interface for building applications.
5 Tips to Get More Out of Your Claude Code with MLflow
MLflow now offers an MCP server, CLIs, and Skills to extend Claude Code, enabling you to trace tokens and monitor tool usage. These five tips will help you transform your Claude coding agent into a transparent and controllable workflow.
v.3.9.0
MLflow 3.9.0 introduces an in-product MLflow Assistant chatbot and a Trace Overview Dashboard for GenAI experiments, enhancing debugging and performance insights. The AI Gateway is revamped for direct tracking server integration, alongside new LLM judge features for online monitoring and custom prompt building.
MLflow 3.9.0rc0 introduces an in-product AI Assistant for debugging and a new Trace Overview Dashboard for GenAI experiments. The AI Gateway is now integrated into the tracking server, and users can configure LLM judges for online monitoring and build custom judges directly in the UI.
 News
NewsClaude Code: 5 Essentials for Data Engineering
The video introduces five essential concepts for using Claude Code in data engineering: the cloud.mmd file for core project information, skills for packaging expertise, commands for predefined prompts, sub-agents for focused tasks, and Model Context Protocol (MCP) for standardized tool interaction. These components help manage context and memory for effective AI-enhanced development.
 Tutorials
TutorialsDatabricks + Cursor IDE: Step-by-Step AI Coding Tutorial
The video demonstrates using Cursor IDE for AI-enhanced Databricks development, focusing on setting up Databricks Connect and leveraging Cursor rules and context for efficient code generation and testing. It shows how to structure projects, write Python and PySpark code, and create unit tests, highlighting the importance of providing clear instructions to the AI agent.
 Events
EventsThe Future of AI Agents with Dario Amodei, Co-founder and CEO, Anthropic at Data + AI Summit

Unity Catalog AI 0.2.0
This release introduces new integrations for Gemini and LiteLLM, enabling Unity Catalog functions as tools for these models. The Databricks client now exclusively supports serverless endpoints and adds support for `requirements`, `environment_version`, and `Variant` types, alongside an overhauled `unitycatalog-autogen` for AutoGen 0.4.x.
Unity Catalog AI 0.1.0
This initial release introduces Unity Catalog AI, providing a core client for managing and executing Unity Catalog functions as GenAI tools. It includes integration packages for popular AI frameworks like LangChain, LlamaIndex, OpenAI, Anthropic, CrewAI, and AutoGen, enabling seamless use of UC functions within these applications.