LakeFlow
Recent items mentioning LakeFlow across the Databricks ecosystem — releases, news, videos, and community Q&A. Updated hourly.
Recent activity highlights LakeFlow's expanding capabilities, particularly with Lakeflow Connect for data ingestion, including new native connectors for platforms like TikTok, Meta Ads, and Google Ads 9, and specific integration questions around PostgreSQL 12. Users are actively exploring advanced use cases such as triggering full refreshes in Lakeflow Connect pipelines 5 and promoting pipelines across environments 7. LakeFlow pipelines are also being leveraged for cutting-edge applications, like transforming raw video into searchable, AI-ready intelligence for public sector agencies 10.
Generated daily from the 10 most recent items mentioning LakeFlow. Click any [N] to jump to the source.
lakeflow connect postgres sql
lakeflow connect postgres sql in uae north
 Tutorials
TutorialsMastering Joins In Apache Spark: Complete Deep Dive
The video provides a deep dive into four Apache Spark physical join strategies: Sort Merge Join, Broadcast Hash Join, Shuffle Hash Join, and Broadcast Nested Loop Join. For each join, it explains the conditions for Spark's selection, visualizes its step-by-step internal mechanics, and demonstrates its appearance in Spark's physical plan and UI.

Trigger a full refresh in a lakeflow connect pipeline with a job
Documentation issue: Invalid JSON example in Lakeflow Connect multi-destination pipeline
How to promote Lakeflow Connect and Spark Declarative Pipeline to a higher environment
From Business Requirements to Lakeflow Pipelines: A Governed Metadata-Driven Delivery Pattern
Lakeflow connect Native connectors (tik, meta ads, Google Ads) - one table per account
How Databricks is turning video into searchable, actionable intelligence
Databricks now enables transforming raw video into searchable, AI-ready intelligence for public sector agencies. This is achieved through VLMs, serverless GPUs, and Lakeflow pipelines to automatically detect, truncate, and summarize key video moments, supporting real-time analysis for public safety and infrastructure.
 News
NewsWhat’s coming next to Free Edition
Databricks announces the availability of Genie, GPUs, Agent Hooks, Lakehouse, and Lake Flow Designer on its Free Edition. This update provides virtually all of Databricks' production platform features for free, enabling users to learn and build data and AI projects.
Lakeflow Connect - Pending ‘full refresh’ process that needs to be removed in gateway pipeline.
 Events
EventsUnlocking agentic data engineering with Lakeflow + Genie
The video introduces Lakeflow as a unified, open data engineering stack that simplifies data transformation, ingestion, and orchestration through declarative pipelines, no-code tools, and managed services. It also announces Genie Zero Ops, an AI agent that automates data operations by autonomously detecting, diagnosing, and verifying fixes for data incidents and PII exposures within the data plane.
Lakeflow SDP (DLT) produce external tables, or only UC-managed
 Events
EventsRecap of product announcements from Data + AI Summit 2026 | Day 1
Databricks announced several new products and features at the Data + AI Summit 2026, Day 1, including the Genetic Data Foundation, Lakehouse RT, Lake Base with disaster recovery, Lake Flow, Genie Ontology, Unity AI Gateway, Omnigent, and various Genie agents (Genie 1, Genie Code, Genie Agents). They also introduced new applications like Lake Watch for SIM and Customer Lake for CP.
Adhoc Table Refresh in Lakeflow Spark Declarative Pipelines (SDP)
What’s coming next to Free Edition
Databricks Free Edition now includes every core practitioner feature, expanding with Genie Code, GPUs, Lakebase, Lakeflow Designer, and Agent Bricks. This gives users a complete, free toolkit for building end-to-end data and AI projects.

What is data pipeline architecture?
Data pipeline architecture separates ingestion, transformation, storage, and serving into distinct layers, with ELT largely replacing ETL as the dominant approach. Databricks unifies batch and streaming pipelines on a single platform (Lakeflow + Delta Lake + Unity Catalog), eliminating duplicate infrastructure and governance gaps.
Lakeflow: A new era of agentic data engineering
Lakeflow unifies ingestion, transformation, and orchestration under Unity Catalog, providing a single source of trusted, real-time context for agentic AI. It offers high-performance ingestion from 100+ sources, real-time streaming, visual pipeline building with Lakeflow Designer, and AI-powered authoring and operations with Genie Code and Genie ZeroOps.
 Events
EventsDatabricks News: CLI v 1.0.0, AI-tools, databricks Docker, DABs UI sync, mutators
The video demonstrates new Databricks features, including the GA release of CLI 1.0.0, UI sync for DABs, Python mutators for bundle extension, and new Docker image options for custom runtimes. It also covers serverless pipeline orchestration, enhanced autoscaling for Lakebase and apps, serverless interactive execution timeout, and auto-scoping for access tokens.
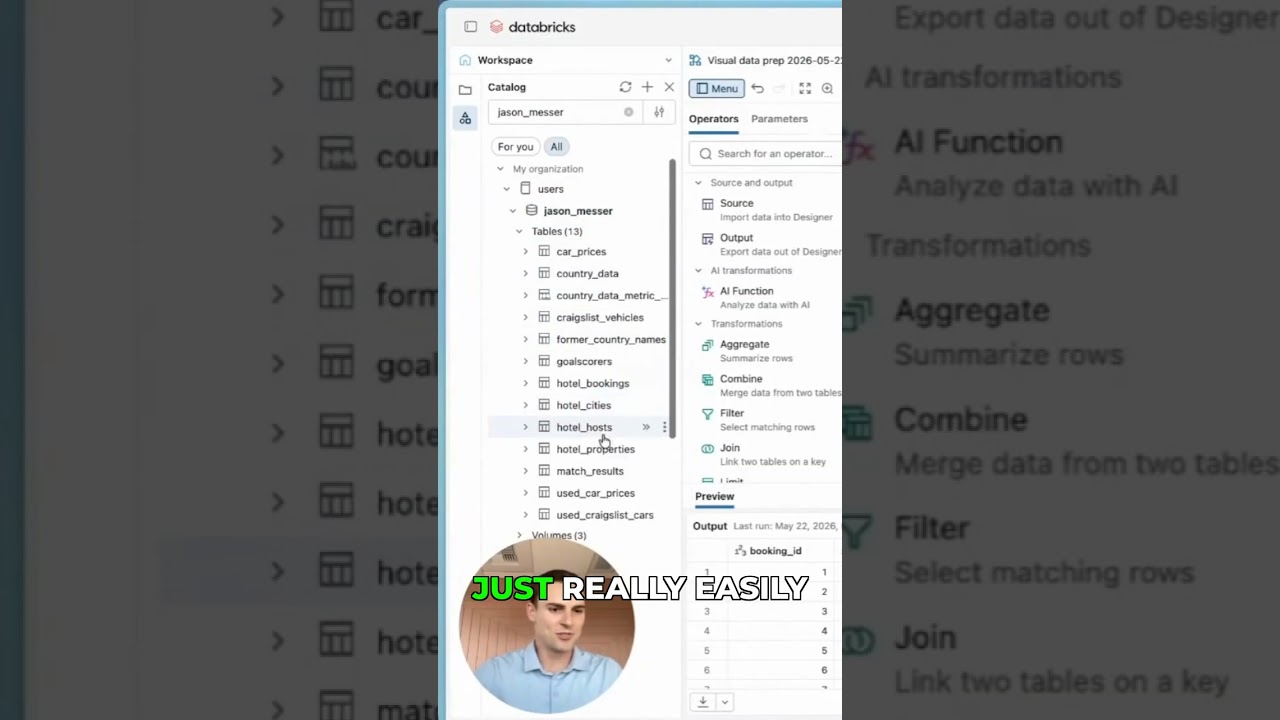 Tutorials
TutorialsPro Tip: Add Multiple Tables Fast! 🚀
Users can quickly add multiple tables to a canvas by dragging them directly from the Catalog Explorer left panel. This method streamlines the process of adding several tables from the same schema or catalog, avoiding the need to create individual source nodes.
Turning Lakeflow Jobs into an SLO Dashboard with System Tables
Building a Real-Time Field Sales App on Databricks with Lakeflow, Lakebase, and Mosaic AI
Lakeflow Connect: Managed Ingestion Without the Pipeline Tax
My experience replacing a Postgres → Kafka → DMS → S3 pipeline with Lakeflow Connect
[Lakeflow Spark Declarative Pipelines] - Compatibility Mode not working
Automating Databricks Lakeflow Connect Pipelines for CDC Databases
Operating PostgreSQL CDC on AWS RDS with Lakeflow Connect
The experimental open command now supports opening a wider range of Databricks resource types directly in the workspace. Databricks Bundles gain a new --select flag for partial deployments, improved retry logic for transient HTTP errors, and support for Terraform references.
Enable CDC in Lakeflow Connect Tables
Automate Lakeflow connect to ingest 300 tables not manually
What’s new in the Lakeflow Pipelines Editor
 Tutorials
TutorialsThe New Databricks Lakeflow Designer Is a Game Changer!
Databricks Lakeflow Designer is a visual data preparation tool that allows users to create, add, and transform data using a no-code drag-and-drop UI or AI-powered Genie Code. The video demonstrates how to import data from various sources, profile data, perform complex transformations like data type conversions and sentiment analysis, and then deploy the resulting production-ready PySpark code for scheduling or integration into existing pipelines.
Lakeflow SDP equivalent of whenNotMatchedBySource
How to get notebooks in courses? - Build Data Pipelines with Lakeflow Spark Declarative Pipelines
Databricks Lakeflow Declarative Pipelines now has pipeline parameters [Beta]
Hey everyone, I noticed Databricks has docs for **Pipeline parameters in Lakeflow Spark Declarative Pipelines**: [https://docs.databricks.com/aws/en/ldp/parameters](https://docs.databricks.com/aws/en/ldp/parameters) A few things worth to mention: * Pipeline parameters feature is currently available only for SQL source code. * Parameters are key-value pairs and values are always strings. * They can be defined as defaults in pipeline settings. * They can be overridden when starting an update, from the UI, API, or a pipeline task in a Job. * Job-level parameters can be pushed down into pipeline tasks. * Parameter precedence is: job run parameters > job parameters > pipeline task parameters > pipeline defaults. * Named parameter syntax seems to be **SQL-only** for now. * There is an important limitation: **parameterized date ranges can accidentally force full refreshes instead of incremental processing, depending on the predicate.** `-- Triggers a full refresh on each update` `CREATE OR REFRESH MATERIALIZED VIEW recent_orders AS` `SELECT * FROM orders` `WHERE order_date >= :start_date AND order_date < :end_date;` https://preview.redd.it/94by275fto3h1.png?width=876&format=png&auto=webp&s=ea639e28cbc9511f98c456d1b7414ff0ed743d5c
Document Intelligence on Databricks
80% of enterprise data is locked inside PDFs, scans, emails and contracts and most teams still treat it as someone else's problem. Document Intelligence on Databricks changes that. One SQL function (ai\_parse\_document), governed by Unity Catalog, integrated with Lakeflow for ingestion, Agent Bricks for structured extraction, and Vector Search for RAG. No stitched-together OCR vendors, no brittle Python glue, no separate platform to govern. I put together with [Archika Dogra](https://www.linkedin.com/in/archikadogra/) a walkthrough showing how it actually works end-to-end from a folder of raw PDFs to queryable Delta tables and downstream agents. ▶️ [https://youtu.be/sdG73gI143c](https://youtu.be/sdG73gI143c) Curious to hear what use cases you're tackling invoices, contracts, claims, technical docs? Drop them in the comments.
 Tutorials
TutorialsThe Future of Finance Operations Starts Here
The video demonstrates how Databricks' financial lakehouse solution addresses common finance data challenges like fragmentation and slow analysis. It showcases features like Unity Catalog for data governance, Lake Flow for pipeline management, and Genie Spaces for natural language querying of financial data.
 Events
EventsDatabricks News: Lakeflow Designer, UV package manager, DABs templates, Genie scheduled tasks
Databricks introduces Lakeflow Designer for visual data preparation, though its generated code is messy; a workaround uses Genie to convert the visual workflow into clean PySpark/SQL notebooks. The UV package manager significantly speeds up package installations on Databricks serverless runtimes, and DABs templates allow for standardized, customizable Databricks Asset Bundles.
 News
NewsMay 2026 Databricks Updates: No Code ETL, New GPUs and Death of the Dashboard
Databricks announced several updates including AI Prep Search for document chunking and vector database preparation, SQL vector functions for embedding mathematics, and the general availability of multi-table transactions. They also introduced Lakeflow Designer for visual, no-code data pipeline creation and updated their serverless GPU offerings to include H100s.
The Rise of Sports Intelligence: How the Lakehouse Turns Tracking Data into Competitive Advantage
Pro teams now leverage the Lakehouse to transform exploding tracking and biomechanical data into sports intelligence, driving real-time decisions on the court, in training, and in the front office. The Databricks Data Intelligence Platform acts as the governed "sports brain," unifying diverse data with Lakeflow, Unity Catalog, ML, and AI Search to power proactive injury management, coaching insights, and next-gen fan experiences.
 Releases
ReleasesIntroducing Databricks Document Intelligence
Databricks Document Intelligence is a new solution for extracting, processing, and analyzing unstructured data from documents using large language models. It offers a unified platform for document processing, including data extraction, summarization, and question answering, with a focus on accuracy and scalability.
 News
NewsDatabricks News: watermark-based incremental ingestion, MCP in AI gateway, Genie, Vector Search
Databricks now offers watermark-based incremental ingestion from SQL databases without change data feed, allowing for efficient data updates and soft deletion handling. The AI Gateway supports custom MCP servers, enabling integration with external APIs like GitHub for enhanced AI application development.
Agentic Data Engineering with Genie Code and Lakeflow
Genie Code, an autonomous AI partner for data engineers, is now integrated directly into Lakeflow. Data engineers can leverage Genie Code within Lakeflow's Pipeline Editor and Jobs for the full data engineering lifecycle, from development and orchestration to monitoring and debugging.
Announcing the Public Preview of Lakeflow Designer
Lakeflow Designer is now in Public Preview, offering a visual, no-code, AI-native interface for data preparation and analysis directly within Databricks. It leverages Unity Catalog for governance and generates production-ready code, providing step-by-step data previews for easier review of AI-generated transformations.
 Tutorials
Tutorials54 Zerobus Ingest Lakeflow Standard Connector | Ingest Streaming data directly into Delta Table
The video demonstrates how to use Databricks Zero Bus Ingest, a push-based API, to directly stream various data types like IoT, event, and telemetry data into Unity Catalog Delta tables. It highlights Zero Bus Ingest's ability to simplify streaming ingestion by eliminating the need for intermediate message buses and managing their infrastructure.
 News
NewsDatabricks News: Free Tier, Multi-statement transactions, Declarative Automation Bundles, Genie Code
Databricks now offers a free tier for Lakeflow Connect, providing 100 DBUs per day per workspace, and has introduced multi-statement transactions in Unity Catalog that ensure atomicity with rollback capabilities. The platform also announced a Databricks One mobile app, a new AI runtime with pre-installed tools for GPU use cases, and enhanced Genie Code that understands project structure for automated development tasks. Additionally, Databricks Asset Bundles are now called Declarative Automation Bundles and use a faster direct engine, and a new 5X-Large SQL warehouse is available for processing terabytes of data.
 Tutorials
TutorialsDatabricks AI Dev Kit Demo - Install, DataGen, SDP, Dashboard
The video demonstrates installing the Databricks AI Dev Kit on a Mac, then uses it to generate synthetic data, create serverless Spark declarative pipelines for a medallion architecture, and build a Databricks dashboard based on the generated data. It highlights how the AI Dev Kit leverages skills and an MCP server to automate these development tasks.
 Tutorials
Tutorials53 Lakeflow Connect SQL Server Managed Connector | Ingest Data using Databricks native connectors
The video demonstrates how to ingest data from SQL Server into Databricks using Lakeflow Connect's managed connector, covering the setup of a SQL Server database, user permissions, and enabling change tracking/change data capture (CT/CDC). It then walks through configuring the Databricks connection, creating gateway and ingestion pipelines, and showcasing how SCD Type 2 changes are automatically managed.
 Tutorials
TutorialsDatabricks End-To-End Project | Zero-To-Expert | Streaming, AI, Lakeflow, Unity Catalog, AI/BI
This video demonstrates building an end-to-end restaurant analytics platform on Databricks, covering streaming and batch data ingestion, AI-powered sentiment analysis, and dashboard creation. It teaches how to use Unity Catalog, Lake Flow Connect for CDC, Spark declarative pipelines for real-time data from Event Hub, and how to construct a medallion architecture with fact and dimension tables.
 News
NewsDatabricks Breaking News: 2026 Week 3: 12 January 2026 to 18 January 2026
Databricks Runtime 18 is now Generally Available, offering Spark 4.1 and improved identifier/parameter maker availability. New features include Lakeflow Connect for row filtering during ingestion, Codex models (GBT Codex Max and Mini) for code development, and Databricks One improvements like favorites and data preview in Gen Rooms.
 News
NewsVibe-Engineering LakeFlow Pipelines, the Advancing Analytics Way
Advancing Analytics introduces Lake Forge, an engineering framework that uses LLMs and an agentic workflow to generate standardized LakeFlow pipeline templates from data specifications. This system aims to enable scalable, repeatable, and supportable data pipeline creation by balancing AI-driven "vibe coding" with human-engineered guardrails and validation loops.
 News
NewsDatabricks Breaking News: Week 51: 15 December 2025 to 21 December 2025 #databricks news
Databricks introduces new Lakeflow Connect features, including custom logic for declarative pipelines and new connectors for incremental data import from sources like Confluence, PostgreSQL, and MySQL. The platform also announces the deprecation of legacy features like Hive Metastore and DBFS for new accounts, alongside updates to Lakehouse ACLs, job scheduling from notebooks, flexible node types for cluster deployment, and expanded resource assignment in Databricks apps.
 News
NewsDatabricks Breaking News: Week 50: 8 December 2025 to 14 December 2025 #databricks news
Databricks now supports native reading and writing of Excel files in PySpark, SQL, and Autoloader, including features like sheet listing and range targeting. Additionally, Databricks Runtime 18 is available in beta, introducing improvements for streaming queries and new system columns for job tables, alongside a new Legase experience with project and branching capabilities for transactional databases.
 Tutorials
Tutorials52 Lakeflow Spark Declarative Pipelines | New Pipeline Code Editor | AUTO CDC |External Target Sinks
Databricks' LakeFlow Spark Declarative Pipelines (SDP), formerly Delta Live Tables (DLT), offers a unified solution for data ingestion, transformation, and orchestration, now open-sourced with Apache Spark 4.1. The video demonstrates using the new pipeline code editor to build SDPs in Python and SQL, showcasing features like auto CDC (formerly apply changes) and external target sinks.
 Events
Events[Demo] Lakeflow Designer: No-Code ETL, Powered by the Data Intelligence Platform
Lakeflow Designer allows users to create ETL pipelines using a no-code approach. It features a "transform by example" assistant that can generate data transformations from a screenshot of desired output.


