Simplify Data Conversion from Spark to TensorFlow and PyTorch
Description
In this talk, I would like to introduce an open-source tool built by our team that simplifies the data conversion from Apache Spark to deep learning frameworks. Imagine you have a large dataset, say 20 GBs, and you want to use it to train a TensorFlow model. Before feeding the data to the model, you need to clean and preprocess your data using Spark. Now you have your dataset in a Spark DataFrame. When it comes to the training part, you may have the problem: How can I convert my Spark DataFrame to some format recognized by my TensorFlow model? The existing data conversion process can be tedious. For example, to convert an Apache Spark DataFrame to a TensorFlow Dataset file format, you need to either save the Apache Spark DataFrame on a distributed filesystem in parquet format and load the converted data with third-party tools such as Petastorm, or save it directly in TFRecord files with spark-tensorflow-connector and load it back using TFRecordDataset. Both approaches take more than 20 lines of code to manage the intermediate data files, rely on different parsing syntax, and require extra attention for handling vector columns in the Spark DataFrames. In short, all these engineeri…
Description from YouTube. Full content on the video page.
More from Databricks
 News
NewsApache Iceberg V3 on Databricks: From Ingestion to Analytics
The video demonstrates Apache Iceberg v3 on Databricks, showcasing how its new variant column type natively handles semi-structured data and how row-level concurrency enables simultaneous data ingestion and corrections. It also highlights cross-platform data accessibility from open-source Spark via the Iceberg REST catalog, ensuring no vendor lock-in.
 News
NewsDatabricks Genie for Marketing
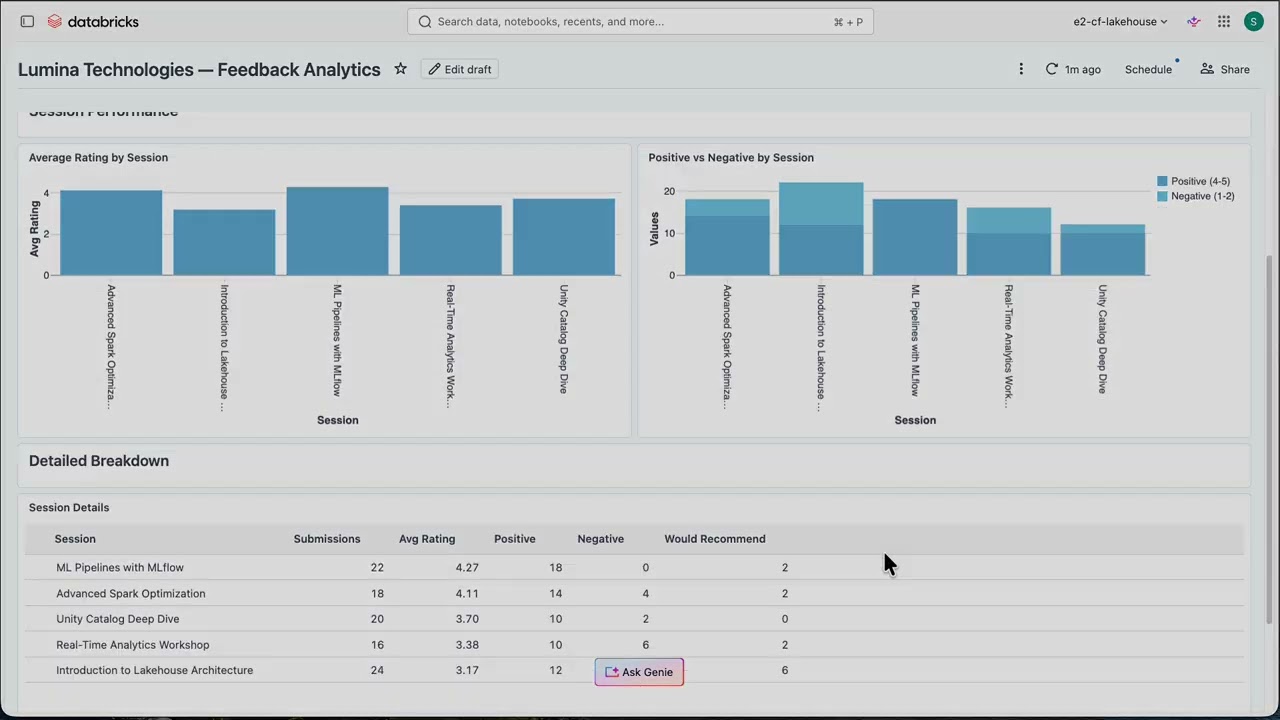
Databricks' AI BI Genie allows non-technical marketers to converse with their Customer 360 data using natural language, enabling quick insights into marketing performance and campaign optimization. It helps identify issues like audience saturation and recommends budget reallocation by analyzing data and providing reasoning for its suggestions.
 News
NewsGovern MCP servers in Databricks #databricks #mcp #aigovernance
Databricks Unity AI Gateway now governs MCP servers, centralizing their management alongside built-in foundation models and LLMs. This integration allows for easier governance and orchestration of various AI components and agents within Databricks.
 News
NewsHow Suntory Turns Data into Faster Decisions with Databricks
Suntory uses Databricks to integrate diverse datasets, including internal sales, macroeconomic factors, and consumer behavior, into "Project Brain" for faster decision-making and product launches. The company also implements an all-employee upskilling program, "Manabi no Michi," to empower its workforce to leverage AI for improved performance and efficiency.
 News
NewsAIA Group x Databricks: Turning Regulated Data into Real-Time Intelligence
AIA Group leverages Databricks to manage regulated data across 18 markets, addressing challenges like data residency and varying tech maturity with features like Unity Catalog for governance. The platform enables real-time intelligence for investment decisions, fraud detection, and personalized agent coaching, with future plans for conversational analytics and autonomous AI.
 Tutorials
TutorialsConnect Google Sheets to Databricks
The Databricks Google Sheets add-in allows users to explore, import, and refresh governed data from the Databricks Lakehouse directly within Google Sheets. It demonstrates how to browse Unity Catalog, select tables or metric views, apply filters, schedule data refreshes, and use direct SQL queries with parameters.