Asset Bundles
Recent items mentioning Asset Bundles across the Databricks ecosystem — releases, news, videos, and community Q&A. Updated hourly.
Databricks Asset Bundles (DABs) have seen significant advancements, with the direct deployment engine now Generally Available and the default for new deployments 6. Recent updates introduce version and branch protection for DABs 13, UI sync capabilities 57, and new deployment mode fields in SDKs 910. Additionally, the Databricks AI Dev Kit Power offers one-click setup to integrate Kiro IDE with the platform, leveraging Unity Catalog metadata for AI-assisted development 8.
Generated daily from the 10 most recent items mentioning Asset Bundles. Click any [N] to jump to the source.

Asset Bundles Setup
 Events
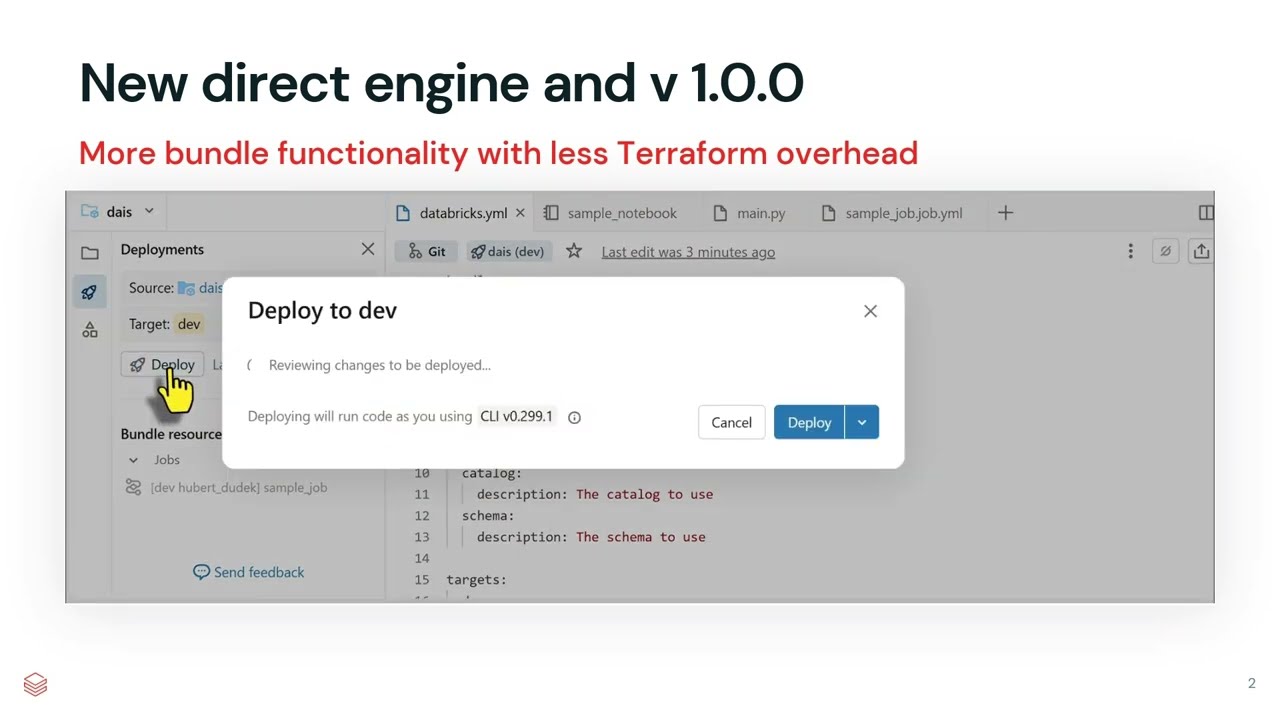
EventsDatabricks News: CLI v 1.0.0, AI-tools, databricks Docker, DABs UI sync, mutators
The video demonstrates new Databricks features, including the GA release of CLI 1.0.0, UI sync for DABs, Python mutators for bundle extension, and new Docker image options for custom runtimes. It also covers serverless pipeline orchestration, enhanced autoscaling for Lakebase and apps, serverless interactive execution timeout, and auto-scoping for access tokens.
UI sync back to DABs
The experimental open command now supports opening a wider range of Databricks resource types directly in the workspace. Databricks Bundles gain a new --select flag for partial deployments, improved retry logic for transient HTTP errors, and support for Terraform references.
Bring Databricks into Kiro IDE with the AI Dev Kit Power
The Databricks AI Dev Kit Power now offers a one-click setup to integrate Kiro IDE with the full Databricks platform, providing AI-assisted development grounded in your workspace's Unity Catalog metadata. This new path, alongside a lighter PAT-based option, ensures your AI assistant writes SQL with actual columns and respects all row, column, and tag-based grants.
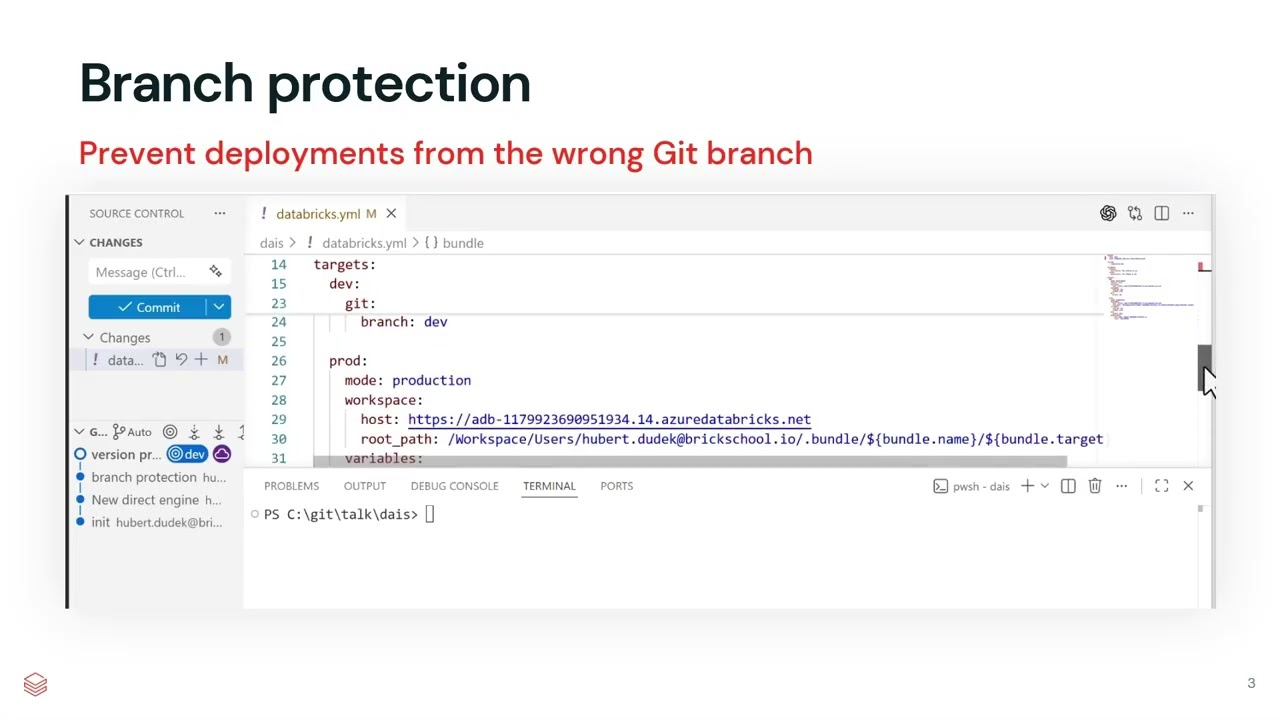
Databricks Asset Bundles now support a DeploymentMode field for both Deployment and Version objects. Workspace settings include new fields for CollaborationPlatformConnectivity and EffectiveCollaborationPlatformConnectivity.
This release adds new fields for deployment mode in Databricks Asset Bundles and collaboration platform connectivity settings. These changes provide more visibility and control over bundle deployments and workspace integration settings.
Best resources to learn Databricks
hi! what are the best resources to learn Databricks from scratch up to management of infra (cluster), optimization of billing, asset bundles, etc? Many thanks.
This release introduces a new Databricks Asset Bundles service and adds `revert()` to Lakeview dashboards and `undelete_branch()` to Postgres. It also includes breaking changes to the `tags` field in Marketplace listings and pagination for Cluster events.
OAuth tokens for interactive logins are now stored in OS-native secure stores by default, requiring re-authentication after upgrading. A new `databricks aitools` command group is introduced for installing Databricks skills into coding agents.
This release introduces a new bundle package and workspace-level service for managing Databricks Asset Bundles. It also adds an MtlsConfig field to ml.AuthConfig for mTLS authentication configurations.
 Events
EventsDatabricks News: Lakeflow Designer, UV package manager, DABs templates, Genie scheduled tasks
Databricks introduces Lakeflow Designer for visual data preparation, though its generated code is messy; a workaround uses Genie to convert the visual workflow into clean PySpark/SQL notebooks. The UV package manager significantly speeds up package installations on Databricks serverless runtimes, and DABs templates allow for standardized, customizable Databricks Asset Bundles.
The `vector_search_endpoints` configuration and commands now use `target_qps` instead of `min_qps`, requiring updates to `databricks.yml` and CLI invocations. Authentication commands received several usability improvements, including better keyring handling, clearer profile selection, and improved reporting of token storage locations.
Release: v2.10.7 (#1895)
This release adds initial remote development compatibility and renames "Databricks Asset Bundles" to "Declarative Automation Bundles." It also fixes issues with profile management and sign-in, and updates the Databricks CLI.
 News
NewsDatabricks News: watermark-based incremental ingestion, MCP in AI gateway, Genie, Vector Search
Databricks now offers watermark-based incremental ingestion from SQL databases without change data feed, allowing for efficient data updates and soft deletion handling. The AI Gateway supports custom MCP servers, enabling integration with external APIs like GitHub for enhanced AI application development.
 Community
CommunityFrom Notebook to Production: MLOps Quickstart
The video demonstrates how to apply MLOps best practices on Databricks using a quickstart repository, covering data ingestion, feature preprocessing, model training, deployment, and inference. It showcases Databricks tools like MLflow and Unity Catalog for managing the ML lifecycle, including version control, experiment tracking, model governance, and automated deployment across development and production environments.
 News
NewsDatabricks News: AUTO CDC, Workspace skills, Ask Genie, and Type widening
Databricks introduces Auto CDC for efficient change data feed processing, notebook and govern tags for better organization, and workspace skills for Ask Genie to customize its responses. Databricks also adds type widening for streaming tables, allowing data types to automatically adjust to larger incoming values.
 News
NewsDatabricks News: Excel add-in, Metrics Views UI, and Quality Monitoring
Databricks announced Lake Watch for cybersecurity, new dynamic dropdown filters in SQL editor, and improved quality monitoring with null value scanning and automated alerts. The video also demonstrates a new UI for defining metric views, an Excel add-in for data preview and import, and the ability to publish dashboards as public web pages.
 News
NewsDatabricks News: Free Tier, Multi-statement transactions, Declarative Automation Bundles, Genie Code
Databricks now offers a free tier for Lakeflow Connect, providing 100 DBUs per day per workspace, and has introduced multi-statement transactions in Unity Catalog that ensure atomicity with rollback capabilities. The platform also announced a Databricks One mobile app, a new AI runtime with pre-installed tools for GPU use cases, and enhanced Genie Code that understands project structure for automated development tasks. Additionally, Databricks Asset Bundles are now called Declarative Automation Bundles and use a faster direct engine, and a new 5X-Large SQL warehouse is available for processing terabytes of data.
 News
NewsDatabricks News: unit testing, OneLake federation, scoped access tokens
Databricks now allows creating Unity Catalog domains for business users, running JAR tasks on serverless compute, and federating OneLake data directly into Databricks. The platform also introduces in-workspace Python unit testing, new data connectors like HubSpot and TikTok Ads, and scoped personal access tokens for enhanced security.
 News
NewsDatabricks News: Catalog and External locations in DABS, Schema Evolution, File Events, Queries Tags
Databricks Runtime 18.1 introduces schema evolution for inserts, managed file events for Autoloader, and a simplified `TABLE` syntax for querying. The video also demonstrates new features like the AI Gateway for LLM governance, query tags for tracking, and the GA release of the supervisor agent.
 News
NewsDatabricks Breaking News: 2026 Week 6: 2 February 2026 to 8 February 2026
Databricks introduces agentic data quality monitoring with anomaly detection, LLM judge UI builder for MLflow, and new SQL warehouse features including a default option and activity details. The platform also enhances its assistant to connect with MCP servers, improves Google Sheets integration with pivot table functionality, and adds direct Git deployment and tagging for Databricks apps.
 News
NewsDatabricks Breaking News: 2026 Week 5: 26 January 2026 to 1 February 2026
Databricks now allows triggering materialized views or streaming tables on update, automatically detecting source changes and refreshing the pipeline. MLflow traces can now be stored in Unity Catalog using OpenTelemetry, providing a centralized logging system for experiment data.
 News
NewsDatabricks Breaking News: 2026 Week 4: 19 January 2026 to 25 January 2026
Databricks introduces temporary tables that are Unity Catalog managed, materialized, and allow DML operations, automatically cleaning up after a session or seven days. Materialized views now support refresh policies like incremental strict, which verifies if a view can be incrementally refreshed before deployment.
 News
NewsDatabricks Breaking News: 2026 Week 3: 12 January 2026 to 18 January 2026
Databricks Runtime 18 is now Generally Available, offering Spark 4.1 and improved identifier/parameter maker availability. New features include Lakeflow Connect for row filtering during ingestion, Codex models (GBT Codex Max and Mini) for code development, and Databricks One improvements like favorites and data preview in Gen Rooms.
 News
NewsDatabricks Breaking News: Week 2026 02: 5 January 2026 to 11 January 2026 #databricks news
Databricks now allows changing catalog and schema during dashboard deployments, addressing a previous issue with environment-specific configurations. The Databricks CLI has a breaking change with plan version 2, altering the structure of deployment plans.
 News
NewsDatabricks Breaking News: Week 2026 01: 29 December 2025 to 4 January 2026 #databricks news
Databricks now supports deploying asset bundles from a generated plan, enabling CI/CD integration for review and approval. Unity Catalog introduces new secret grants, and Runtime 18 brings "everywhere" implementations for literal string colling, parameter markers, and identifiers, along with window functions in metrics view and general availability for SQL scripting.
 Releases
ReleasesDatabricks Breaking News: Week 52: 22 December 2025 to 28 December 2025 #databricks news
Databricks introduces a direct mode for asset bundles, offering faster deployments without Terraform, and the Databricks Assistant agent mode is now in public preview, capable of multi-step notebook editing and data analysis. Other updates include single-use refresh tokens for enhanced security, partition columns now included in Parquet files for improved compatibility, and new dashboard features like custom labels, flexible sorting, and Microsoft Teams integration for scheduled reports.
 News
NewsDatabricks Breaking News: Week 51: 15 December 2025 to 21 December 2025 #databricks news
Databricks introduces new Lakeflow Connect features, including custom logic for declarative pipelines and new connectors for incremental data import from sources like Confluence, PostgreSQL, and MySQL. The platform also announces the deprecation of legacy features like Hive Metastore and DBFS for new accounts, alongside updates to Lakehouse ACLs, job scheduling from notebooks, flexible node types for cluster deployment, and expanded resource assignment in Databricks apps.
 News
NewsDatabricks Breaking News: Week 50: 8 December 2025 to 14 December 2025 #databricks news
Databricks now supports native reading and writing of Excel files in PySpark, SQL, and Autoloader, including features like sheet listing and range targeting. Additionally, Databricks Runtime 18 is available in beta, introducing improvements for streaming queries and new system columns for job tables, alongside a new Legase experience with project and branching capabilities for transactional databases.
 News
NewsDatabricks: What’s new in October 2025 #databricks news
Databricks introduces Databricks One, a new business-focused experience with consumer access for dashboards and Genie, alongside updates to Genie for defining relations and extended API endpoints. The platform also adds features like easy conversion of external to managed tables, enhanced Databricks Asset Bundles with policy integration and script execution, and new system tables for MLflow tracking and data classification results.
 News
NewsDatabricks: What’s new in September 2025? #databricks
Databricks now supports geospatial data types (geography and geometry) with new functions for visualization and spatial operations, and introduces serverless GPU clusters for distributed GPU code execution. The platform also offers enhanced notebook features like side-by-side editing and a notebook-specific search, along with new options for managing serverless environments, SQL warehouses, and access requests in Unity Catalog.
 Tutorials
Tutorials51 Setup Azure DevOps Pipeline with Databricks Asset Bundles (DABs) | Complete CICD Process
The video demonstrates how to set up an Azure DevOps pipeline to deploy Databricks Asset Bundles (DABs) to higher environments like QA. It covers configuring service principal permissions, setting up Azure pipeline variables for environment-specific details, and writing the YAML pipeline code to validate and deploy Databricks assets.
 Tutorials
Tutorials50 Databricks Asset Bundles | Configure Production grade DABs | CICD using DABs (IAC)
The video demonstrates how to configure and deploy Databricks Asset Bundles (DABs) for managing Databricks assets like notebooks, jobs, and pipelines across different environments. It covers creating a structured DAB project, defining resources and targets in YAML, and deploying using both the Databricks UI and CLI, including setting up environment-specific configurations and variables.
 News
NewsDatabricks: What’s new in July 2025? Updates & Features Explained! #databricks

 News
NewsHarnessing Databricks Asset Bundles: Transforming Pipeline Management at Scale at Stack Overflow
 News
News




