Databricks SQL
Recent items mentioning Databricks SQL across the Databricks ecosystem — releases, news, videos, and community Q&A. Updated hourly.
Databricks SQL is set to revolutionize real-time analytics with the introduction of Lakehouse//RT and the Raiden engine, promising millisecond performance and massive concurrency directly on lakehouse formats 1. Recent enhancements also include support for query tags to improve cost attribution and context across various tools 8, and new capabilities like incremental REPLACE WHERE flows for targeted data refreshes 4.
Generated daily from the 10 most recent items mentioning Databricks SQL. Click any [N] to jump to the source.
 Releases
ReleasesIntroducing Lakehouse//RT and Reyden — Reynold Xin, Co–founder and Chief Architect
Databricks introduces Lakehouse//RT, a new SQL warehouse powered by the Raiden engine, designed to provide millisecond performance and massive concurrency for real-time analytics directly on data lake formats like Delta and Iceberg. This innovation aims to unify data warehousing and serving stacks, eliminating the need for separate systems and data copies.
DBSQL MCP output limit
Querying Metric Views via Classic/Pro SQL Warehouses
Incremental REPLACE WHERE Flows Brings Targeted Refreshes to SDP and DBSQL
Sciene AI Companion: building an autonomous Customer Success platform on Databricks
Sciene built an autonomous Customer Success platform on Databricks, enabling AI-powered CSMs to standardize and scale work with context-aware emails, meeting decks, and account diagnostics. This end-to-end Databricks solution, leveraging Delta Sharing, Lakebase, and SQL Warehouses, significantly improved productivity and saved up to 6x time on key workflows.
Restrict certain queries on SQL Warehouse
1.12.1
This release exposes Databricks Jobs IDs in dbt's adapter response for better run correlation and adds support for Databricks SPOG vanity URLs. It also fixes issues with streaming tables, materialized views, column-level constraints, and managed Iceberg incremental models.
The experimental open command now supports opening a wider range of Databricks resource types directly in the workspace. Databricks Bundles gain a new --select flag for partial deployments, improved retry logic for transient HTTP errors, and support for Terraform references.
SQL Warehouse stuck on "Cluster Start-up Delayed"
Query Tags: The Context Your Warehouse Queries Have Been Missing
Databricks SQL warehouses now support query tags, enabling cost attribution by team or project and automatic tagging for dbt, PowerBI, and Tableau. Tag queries from any source, including the SQL Editor, Notebooks, Dashboards, APIs, connectors, and drivers.
Databricks SQL connection becomes stale in long-running app
Databricks SQL Just Dropped Some Massive Engine Upgrades for Data Engineers
Announcing Lakebase Change Data Feed (CDF)
Lakebase Change Data Feed (CDF) is now in Public Preview, eliminating pipeline sprawl from operational databases by exposing every table's changes through Unity Catalog Managed Tables. This enables native CDC governed end-to-end without sidecar infrastructure, allowing operational data to function as the native Bronze layer in the medallion architecture.
Debugging a Databricks Federated Query
Hi, I came across an interesting question on the Databricks Community, and I thought I would share my findings in case someone else runs into the same issue. Maybe this will help save some time debugging. The setup was as follows: * SQL Server was registered as a federated connection in Unity Catalog. * Queries were executed directly from Databricks against federated SQL Server tables. * The user who created the thread executed a query using standard date functions such as `YEAR()` and `MONTH()` against a federated table. Example of query that was executed: SELECT MONTH(order_date) AS order_month, YEAR(order_date) AS order_year, COUNT(*) AS total_orders FROM federated_db.sales.orders GROUP BY MONTH(order_date), YEAR(order_date) However, the query failed with the following error: `com.microsoft.sqlserver.jdbc.SQLServerException: 'EXTRACT' is not a recognized built-in function name. at` So, what is happening here? At first glance, this looks confusing because SQL Server does support the `YEAR()` and `MONTH()` functions. As it turns out, in Databricks SQL, `YEAR()` and `MONTH()` are synonyms for the ANSI **EXTRACT()** function. https://preview.redd.it/5grz6yvu7n3h1.png?width=765&format=png&auto=webp&s=19cb791a079ddbbe2eb696f77d1693028d0bd722 That is where the problem occurs: SQL Server does not support the ANSI `EXTRACT()` syntax, so the federated query fails. To work around this, you can try rewriting the query in a way that is compatible with the federated execution path. Alternatively, you can use the **remote\_query()** function, which allows you to run SQL directly against the external database using the native SQL syntax of the remote system. Orignal thread: [Re: Extract SQL function in SQL Server federated d... - Databricks Community - 157392](https://community.databricks.com/t5/data-engineering/extract-sql-function-in-sql-server-federated-database/m-p/157397#M54544)
Announcing the Databricks analytics engineer learning pathway
A new learning pathway for Databricks SQL practitioners is now available on Databricks Academy, covering skills to use the full SQL ETL toolkit for data modeling, pipelines, semantic layers, and conversational agents. Courses are offered in self-paced and instructor-led formats, and are included with any active Databricks Learning Subscription.
MLflow 3.12.0 introduces multimodal tracing, allowing storage and rich rendering of PDFs, audio, and images as artifact attachments in tracing spans. It also adds AI Gateway guardrails to prevent unsafe model inputs/outputs and extends coding agent tracing support to Codex, Gemini, and Qwen.
 Tutorials
TutorialsLakebase - OLTP Workloads on Databricks!
Lakebase is a fully managed, serverless PostgreSQL offering from Databricks that decouples compute and storage, enabling independent scaling, auto-scaling to zero, and deep integration with the Databricks Lakehouse. It supports reverse ETL to bring data from the Lakehouse into Lakebase for OLTP applications and forward ETL to sync transactional data back to the Lakehouse for analytics.
 News
NewsStop Guessing Table Health — Let These Dashboards Tell You
Databricks offers two dashboards for monitoring table health and access: the Table Access Advisor and the Table Health Advisor. These dashboards provide insights into table ownership, read/write patterns, staleness, optimization status, and underlying file structures, helping users identify ghost tables and ensure best practices.
 News
NewsDatabricks News: Free Tier, Multi-statement transactions, Declarative Automation Bundles, Genie Code
Databricks now offers a free tier for Lakeflow Connect, providing 100 DBUs per day per workspace, and has introduced multi-statement transactions in Unity Catalog that ensure atomicity with rollback capabilities. The platform also announced a Databricks One mobile app, a new AI runtime with pre-installed tools for GPU use cases, and enhanced Genie Code that understands project structure for automated development tasks. Additionally, Databricks Asset Bundles are now called Declarative Automation Bundles and use a faster direct engine, and a new 5X-Large SQL warehouse is available for processing terabytes of data.
 Tutorials
TutorialsDatabricks End-To-End Project | Zero-To-Expert | Streaming, AI, Lakeflow, Unity Catalog, AI/BI
This video demonstrates building an end-to-end restaurant analytics platform on Databricks, covering streaming and batch data ingestion, AI-powered sentiment analysis, and dashboard creation. It teaches how to use Unity Catalog, Lake Flow Connect for CDC, Spark declarative pipelines for real-time data from Event Hub, and how to construct a medallion architecture with fact and dimension tables.
 News
NewsDatabricks Breaking News: 2026 Week 6: 2 February 2026 to 8 February 2026
Databricks introduces agentic data quality monitoring with anomaly detection, LLM judge UI builder for MLflow, and new SQL warehouse features including a default option and activity details. The platform also enhances its assistant to connect with MCP servers, improves Google Sheets integration with pivot table functionality, and adds direct Git deployment and tagging for Databricks apps.
SQL warehouses now support "5X-Large" cluster sizes and a higher maximum of 40 clusters. This release also fixes permanent drift for external model credentials in databricks_model_serving and improves dashboard file content change detection.
 News
NewsClaude Code: 5 Essentials for Data Engineering
The video introduces five essential concepts for using Claude Code in data engineering: the cloud.mmd file for core project information, skills for packaging expertise, commands for predefined prompts, sub-agents for focused tasks, and Model Context Protocol (MCP) for standardized tool interaction. These components help manage context and memory for effective AI-enhanced development.
 News
NewsDatabricks: What’s new in September 2025? #databricks
Databricks now supports geospatial data types (geography and geometry) with new functions for visualization and spatial operations, and introduces serverless GPU clusters for distributed GPU code execution. The platform also offers enhanced notebook features like side-by-side editing and a notebook-specific search, along with new options for managing serverless environments, SQL warehouses, and access requests in Unity Catalog.
 Events
EventsIntroducing Lakebridge: Free, Open Data Migration to Databricks SQL
Lakebridge is a free, open, AI-powered tool for migrating data warehouses to Databricks SQL. It works by analyzing the existing environment, converting code using an LLM, migrating data, and then reconciling to validate the migration.
 News
NewsCrypto at Scale: Building a High-Performance Platform for Real-Time Blockchain Data
 Tutorials
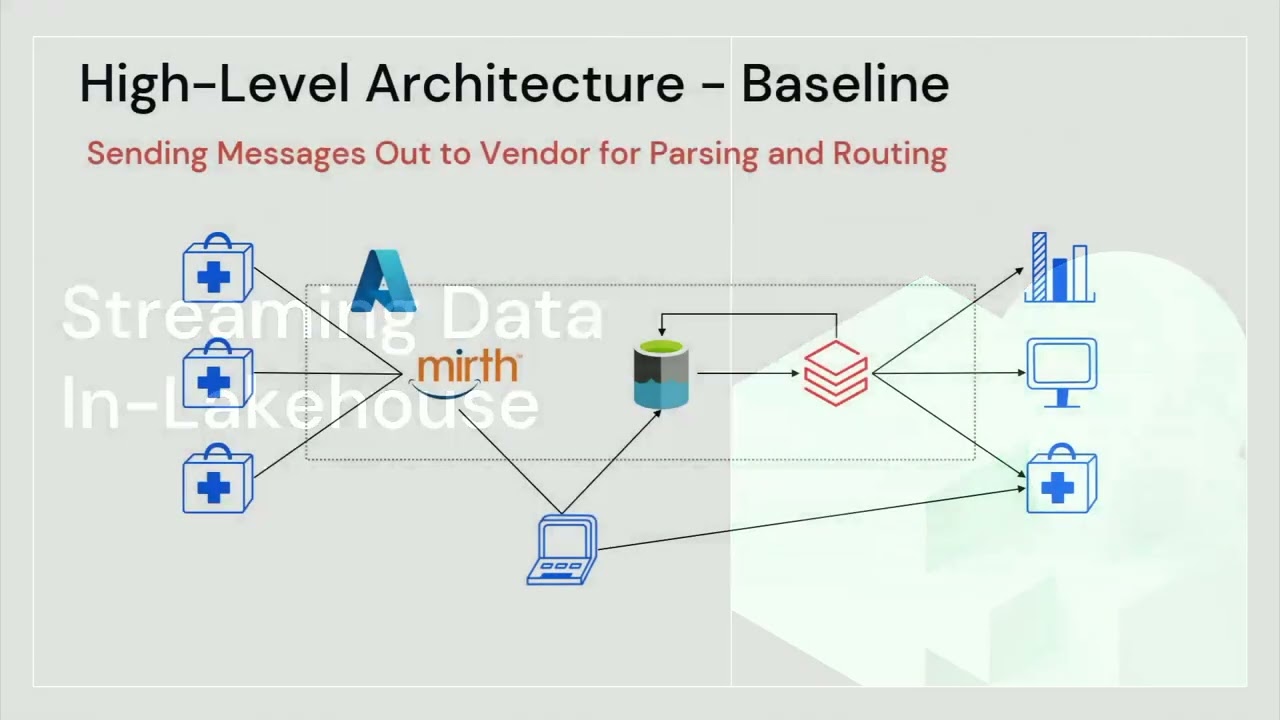
TutorialsHealthcare Interoperability: End-to-End Streaming FHIR Pipelines With Databricks & Redox

 Tutorials
TutorialsDatabricks Metrics - create a semantic layer and improve data engineering


UCX now requires matching account groups to be created before assessment and clarifies Service Principal setup for installation. It also fixes table migration when a default catalog is set and pauses the migration progress workflow schedule by default.

 Tutorials
Tutorials42 Streaming Tables and Materialized Views in DBSQL | Background Working | Schedule data Refresh

 Tutorials
TutorialsHow to read files with Databricks SQL # 5/6 of file handling series


 News
NewsLearnings From the Field: Migration From Oracle DW and IBM DataStage to Databricks on AWS

 News
NewsDatabricks and Delta Lake: Lessons Learned from Building Akamai's Web Security Analytics Product
 News
NewsIncreasing Data Trust: Enabling Data Governance on Databricks Using Unity Catalog & ML-Driven MDM
 News
NewsReal-Time Reporting and Analytics for Construction Data Powered by Delta Lake and DBSQL


 Tutorials
TutorialsDatabricks SQL Serverless Under the Hood: How We Use ML to Get the Best Price/Performance




 Tutorials
Tutorials






