Data Quality
Recent items mentioning Data Quality across the Databricks ecosystem — releases, news, videos, and community Q&A. Updated hourly.
Recent Databricks blogs highlight data quality as a critical factor for successful AI initiatives, emphasizing that poor data quality is a common pitfall to avoid when tying AI investments to business outcomes 1. A modern data governance architecture, combining automated lineage and RBAC, is key to ensuring data quality and regulatory compliance at scale 3. These strategies underscore the importance of clean, governed data and strategic platform consolidation for driving company growth with AI 1.
Generated daily from the 5 most recent items mentioning Data Quality. Click any [N] to jump to the source.
Top 10 AI Business Solutions Driving Company Growth
Discover the top 10 AI business solutions driving company growth, emphasizing the critical role of clean, governed data and strategic platform consolidation. Learn how successful organizations are achieving high returns by tying AI investments to specific business outcomes, avoiding common pitfalls like poor data quality and late governance.
Enterprise Data Strategy Roadmap for Business Outcomes
* A robust enterprise data strategy connects organizational data assets to specific business objectives through governance, architecture, and analytics frameworks that scale with evolving business needs. * Effective data governance, data quality management, and master data manage
Data Governance Architecture: A Complete Blueprint for Modern Organizations
This blueprint details a complete data governance architecture, outlining the policies, roles, and technologies needed to manage data assets. It emphasizes a modern strategy combining automated lineage, RBAC, and federated models to ensure data quality and regulatory compliance at scale.
Pipelines - how are you handling significant schema changes?
Hello - Right now with pipelines you can set things up so you can gracefully handle column additions and safe type conversions (more general type to more specific type). For things like column removals or downcasting, even the most liberal schema evolution setting will throw a failure and require the user manually triage by doing a full reload. I get why this is being done and I agree with the overall philosophy. We should lean on planning and communication because signifiant schema changes mean there is likely an impact downstream and/or to do data quality/meaning. But...... that means we have breaking changes that need to be triaged. In a scenario where we have separate Ops teams potentially operating in a different country, that means we would need to do "staged" failure and reprocessing of the various pipelines. EX: major change in pipeline A means it breaks and requires a full refresh. But A feeds B which feeds C which feeds D. In some situations, that means staged triaging of those expected failures (fix A, then fix B, then fix C, then fix D) - which means labor and perceived extended downtime. - How is everyone managing those kinds of situations? - Is there any possibility of ever setting the pipeline objects to allow for any form of schema change - falling back to a full load as a "last resort" so things auto-heal? (I get why this is not a great option, but at some point this feels like what we'd do manually anyway) Thank you!
Governing AI agents at scale with Unity Catalog
Unity Catalog now governs AI agents at scale, providing a unified layer for identity-aware access, runtime policies, and full auditability across all agent interactions. This extends data governance to AI systems, improving observability, compliance, and trust for models, servers, and data within the lakehouse.
 Community
CommunityHow I Mastered System Design Interviews
This video teaches a six-step framework for mastering data engineering system design interviews, covering requirements gathering, pipeline design, data modeling, storage and file formats, data quality and observability, and pipeline resilience. It demonstrates how to apply this framework with practical examples and back-of-the-envelope calculations to justify design choices.
 News
NewsData + AI Executive Series: Fast 5 — Scaling Real-Time Ops with Databricks at Aer Lingus
Aer Lingus uses Databricks to scale real-time operations, particularly for making critical decisions in their operation control center regarding flight delays and cancellations. They are also exploring using "Agentic" to automate business case creation and review, aiming for a single, governed platform for reusable agents.
Data quality is the AI strategy
Your AI strategy hinges on data quality, starting with fixes to transactional systems. Organizations prioritizing value creation with unified data will benefit most, as tools and models constantly evolve.
Effective strategies to enhance data quality management
Improve data quality with testing, metrics, automation, and a scalable governance framework.
How data transformation improves data quality and analysis
Learn how transformation methods improve data quality, consistency, and analysis at scale with dbt.
Effective strategies to improve data quality across your organization
Databricks practitioners can improve data quality with proven strategies for testing, governance, and scalable analytics workflows. Learn how to implement these effective strategies across your organization.
 News
NewsOpenClaw, Databricks Agentic Data Monitoring & more! | AI Newsround - February 2026 | Advancing AI
The video discusses OpenClaw, an open-source framework for AI agents, and Databricks' new agentic data quality monitoring solution. It also introduces Advancing Analytics' Lake Forge and Pantheon, a framework and AI layer for developing scalable Lake Flow pipelines, and highlights new model releases from Anthropic, Google, and OpenAI.
 News
NewsDatabricks Breaking News: 2026 Week 6: 2 February 2026 to 8 February 2026
Databricks introduces agentic data quality monitoring with anomaly detection, LLM judge UI builder for MLflow, and new SQL warehouse features including a default option and activity details. The platform also enhances its assistant to connect with MCP servers, improves Google Sheets integration with pivot table functionality, and adds direct Git deployment and tagging for Databricks apps.






 News
NewsLakeflow Connect: Smarter, Simpler File Ingestion With the Next Generation of Auto Loader
 News
News125. Databricks | Pyspark| Delta Live Table: Data Quality Check - Expect



 News
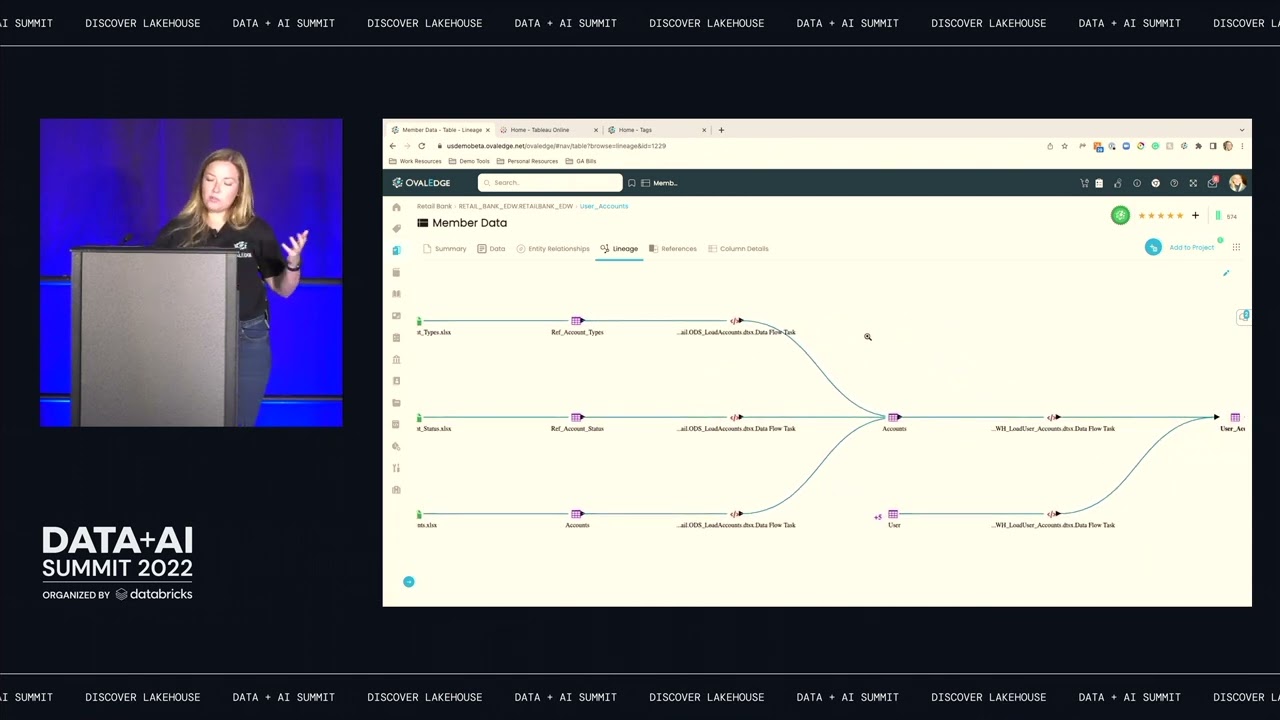
NewsIncreasing Data Trust: Enabling Data Governance on Databricks Using Unity Catalog & ML-Driven MDM

 News
NewsLeveraging IoT Data at Scale to Mitigate Global Water Risks Using Apache Spark™ Streaming and Delta
 News
NewsUS Army Corp of Engineers Enhanced Commerce & National Sec Through Data-Driven Geospatial Insight
 News
NewsSponsored: Matillion | Using Matillion to Boost Productivity w/ Lakehouse and your Full Data Stack
 Community
CommunitySponsored by: Fivetran | Fivetran and Catalyst Enable Businesses & Solve Critical Market Challenges
 News
NewsSponsored by: Anomalo | Scaling Data Quality with Unsupervised Machine Learning Methods
 News
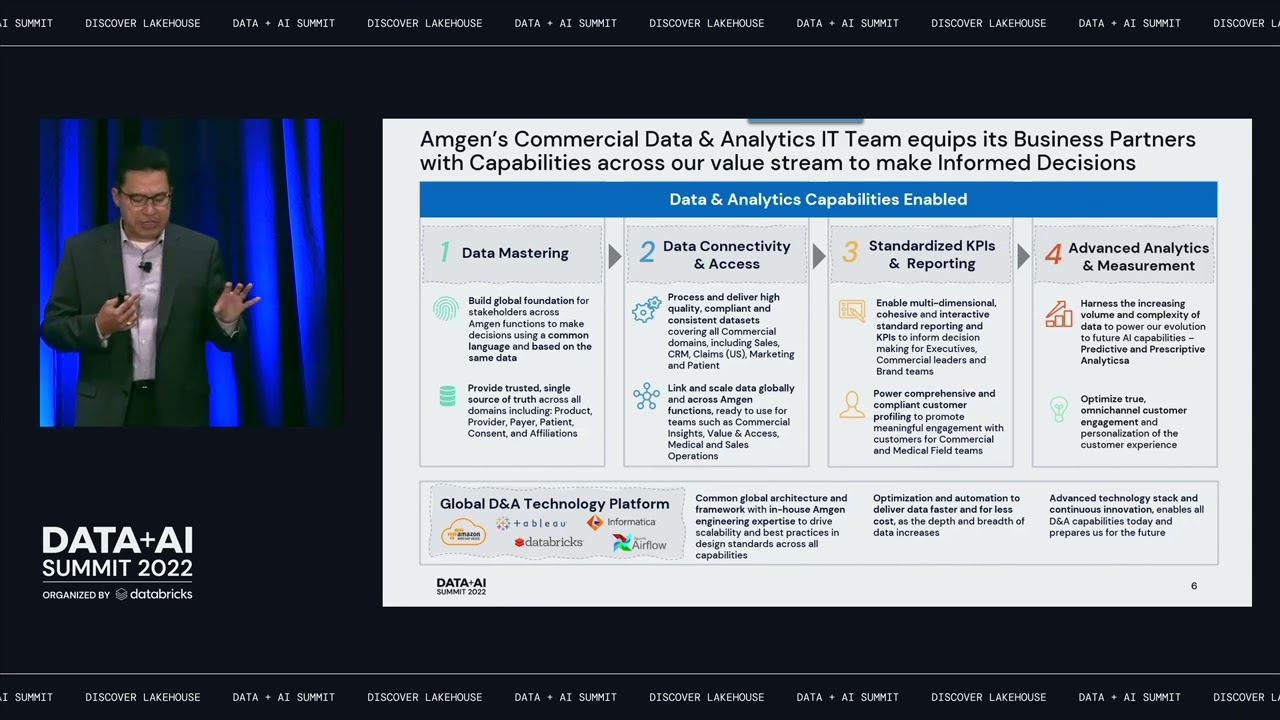
NewsSponsored: Accenture | Databricks Enables Employee Data Domain to Align People w/ Business Outcomes


 News
NewsHow unsupervised machine learning can scale data quality monitoring in Databricks

 News
News